

Authors:
(1) Siqi Kou, Shanghai Jiao Tong University and with Equal contribution;
(2) Lanxiang Hu, University of California, San Diego and with Equal contribution;
(3) Zhezhi He, Shanghai Jiao Tong University;
(4) Zhijie Deng, Shanghai Jiao Tong University;
(5) Hao Zhang, University of California, San Diego.
Table of Links
3. Methodology and 3.1. Preliminary: Jacobi Decoding
3.2. Consistency Large Language Models (CLLMs)
3.3. Acceleration Mechanisms in CLLMs
4. Experiments
4.2. Acceleration Mechanisms in CLLMs
4.4. Limitations and Discussion
5. Conclusion, Impact Statement, and References
A. Illustration of Consistency Loss Learning Objectives
B. Comparison with Baseline Algorithms
C. Pesudo Code for Jacobi Decoding with KV Cache
4.1. Evaluations
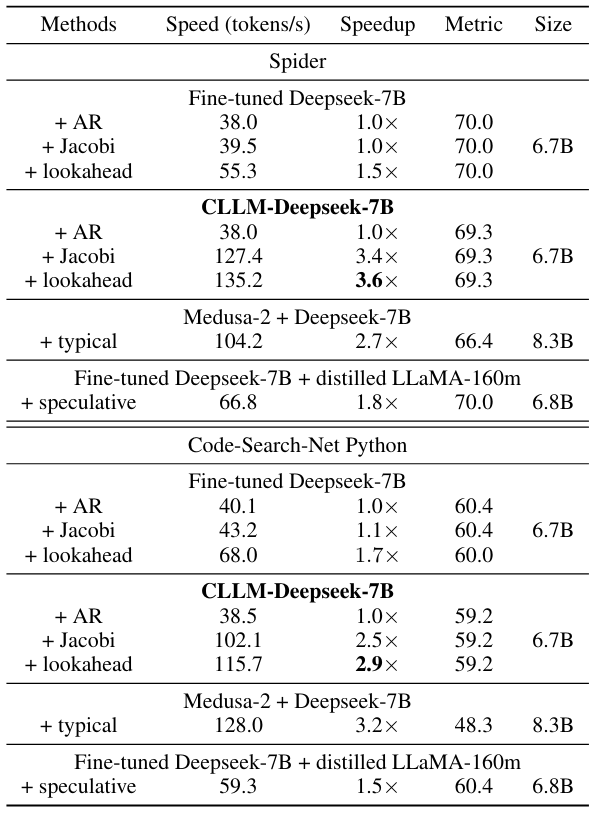
Benchmarks and Setup. We evaluate performance across three domain-specific tasks, including text-to-SQL (Spider) (Yu et al., 2018), Python code generation (Code-search-Python) (Husain et al., 2019) and graduate school math (GSM8k) (Cobbe et al., 2021). To test CLLMs generalizability on open-domain conversational interactions
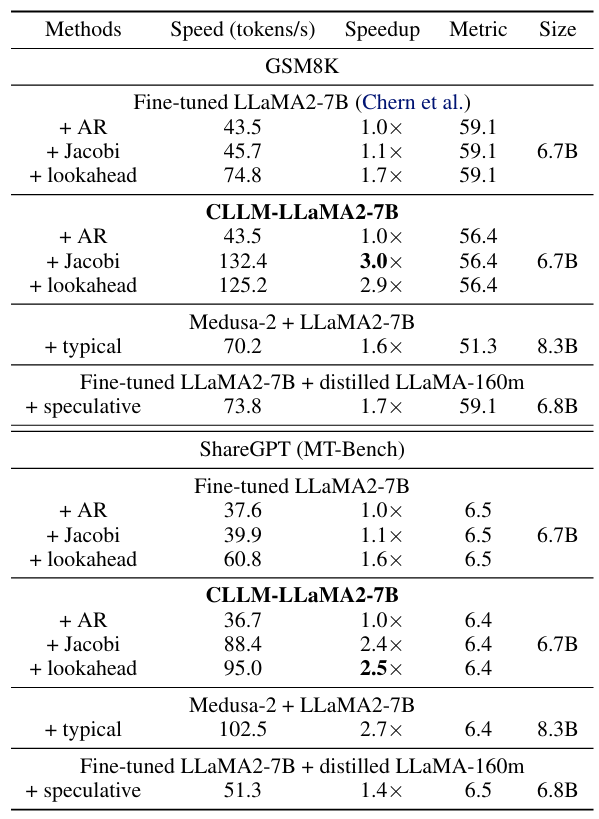
and instruction-following scenarios, we also train CLLMs on ShareGPT[2] data and perform evaluation on the MTbench (Zheng et al., 2023). The performance metrics are the greedy answers’ problem solve rate (test@1) on GSM8K, MT-bench score, execution accuracy on Spider, as well as and strict accuracy (pass@1) on Human-Eval. Additionally, we also run evaluations of CLLMs’ language modeling capability on raw-WikiText2 (Merity et al., 2016) and PTB (Pan et al., 2020).
Reported experiments were conducted using either pretrained coder LLM, Deepseek-coder-7B-instruct (Bi et al., 2024) or LLaMA-2-7B (Touvron et al., 2023a;b) depending on the task. Both training and evaluation are carried out on servers equipped with 8 NVIDIA A100 40GB GPUs and 128 AMD EPYC 7742 64-core processors.
Baselines. In this section, we compare CLLMs with a range of alternative models that employ various strategies to speed up the inference process. This includes Medusa (Cai et al., 2024), which modifies the underlying architecture, and approaches utilizing distilled draft models for speculative decoding (Zhou et al., 2023b; Liu et al., 2023). Alongside these, we also consider fine-tuned baseline models for a comprehensive comparison. Our evaluation tests each model under different decoding paradigms the model is compatible with to thoroughly assess their inference quality and speed. The decoding algorithms include vanilla AR decoding, Jacobi decoding (Song et al., 2021a), speculative decoding (Leviathan et al., 2023), and lookahead decoding (Fu et al., 2024).
Results. To evaluate the performance and inference speedup of CLLMs across various tasks, we conduct an extensive comparison with the SOTA baselines on the three domain specific tasks and the open-domain MT-bench.
Table 1 and Table 2 compare CLLMs against fine-tuned baseline models across three different generation modes: AR decoding, Jacobi decoding, lookahead decoding, and the stronger speculative decoding baseline using a distilled draft model. In both Jacobi and lookahead decoding, CLLMs consistently surpass the baselines. Notably, on the Spider dataset, CLLMs achieve a 3.4× speedup with negligible performance loss using Jacobi decoding. When benchmarked against other SOTA methods for efficient LLM inference, particularly those necessitating training, CLLMs exhibit the ability of fast consistency generation while maintaining lower memory and computational demands with lowest memory consumption in comparison with Medusa and speculative decoding. In these cases, we can still see CLLMs consistently outperform speculative decoding with distilled draft model and achieve better accuracy with comparable and even better inference speedup on datasets like Spider and GSM8K, where collocations are more common. CLLMs can also seamlessly integrate with lookahead decoding, and more speedup is gained compared to lookahead decoding applied in fine-tuned LLMs.
We highlight CLLMs’ advantage over speculative decoding with distilled draft models and Medusa is its high adaptability. This is because CLLMs’ are models tailored for Jacobi decoding. Jacobi decoding requires no modification to the original models. In the contrary, both speculative decoding and Meudsa require either auxiliary components like LM head, tree-based attention mask, or draft model, which usually come with the cost of searching for the optimal configuration. This is further summarized in Table 7.
Moreover, the language modeling results in Table 5 show CLLMs are able to maintain a low perplexity while rendering at least 2× speedup, suggesting CLLMs’ potential to be trained as pre-trained LLM with higher inference efficiency.
This paper is available on arxiv under CC0 1.0 Universal license.
[2] http://www.sharegpt.com.