

The Prompt Patterns That Decide If an AI Is “Correct” or “Wrong”
27 Aug 2025
Benchmarking AI isn’t guesswork—CRITICBENCH uses few-shot chain-of-thought prompts to reveal how accurate LLMs really are.

Why “Almost Right” Answers Are the Hardest Test for AI
27 Aug 2025
Discover how CRITICBENCH tests AI by sampling “convincing wrong answers” to reveal subtle flaws in model reasoning and accuracy.
Why CriticBench Refuses GPT & LLaMA for Data Generation
27 Aug 2025
Inside CriticBench: How Google’s PaLM-2 models generate benchmark data for GSM8K, HumanEval, and TruthfulQA with open, transparent methods.
Why Smaller LLMs Fail at Critical Thinking
27 Aug 2025
Discover CRITICBENCH, the open benchmark comparing GPT-4, PaLM-2, and LLaMA on reasoning, coding, and truth-based critique tasks.
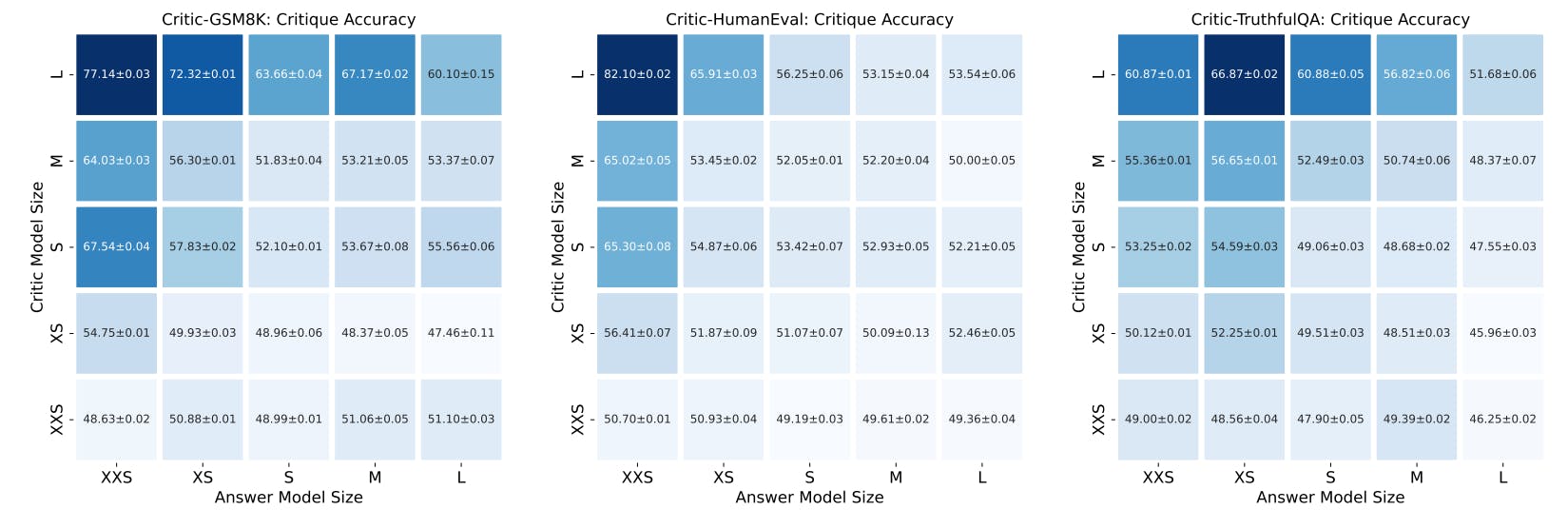
Improving LLM Performance with Self-Consistency and Self-Check
27 Aug 2025
Can AI critique itself? This study shows how self-check improves ChatGPT, GPT-4, and PaLM-2 accuracy on benchmark tasks.
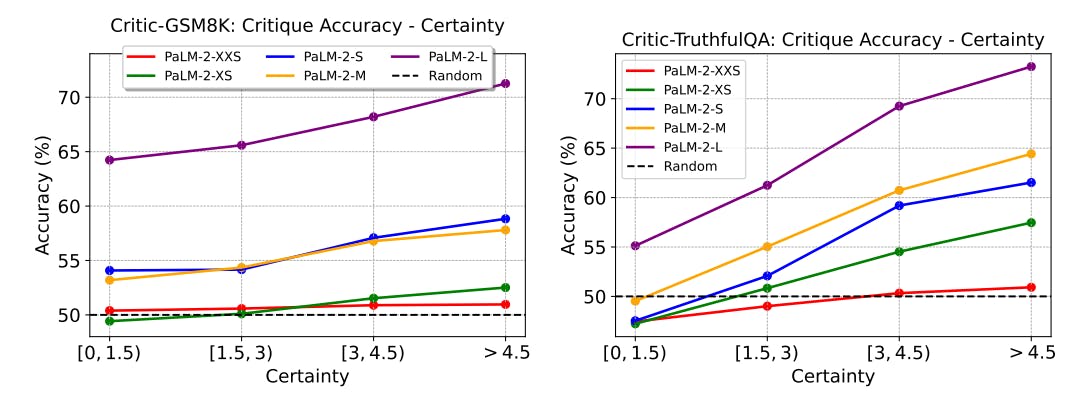
Critique Ability of Large Language Models: Self-Critique Ability
25 Aug 2025
How well can AI critique its own answers? Explore PaLM-2 results on self-critique, certainty metrics, and why some tasks remain out of reach.
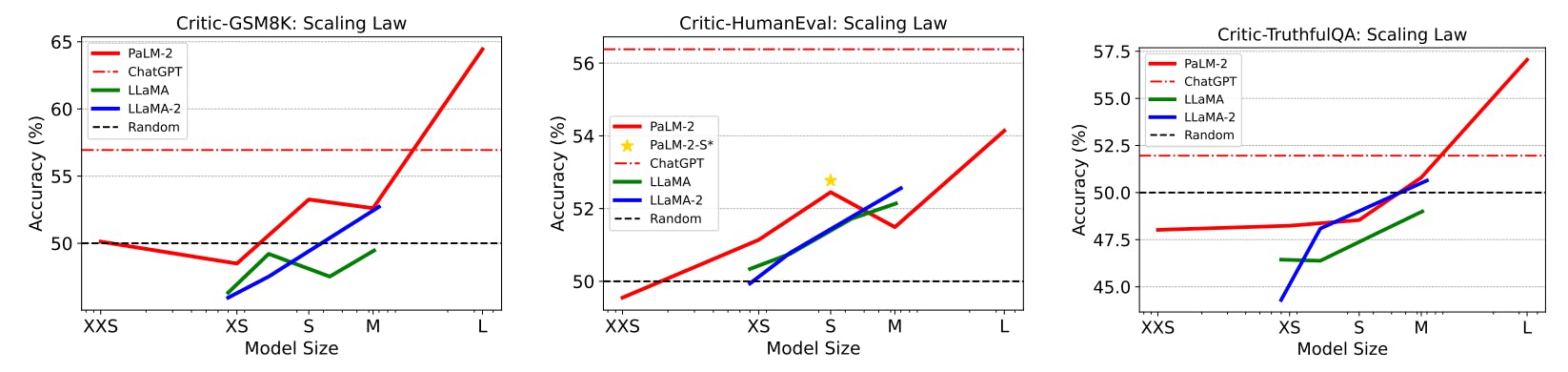
Why Even the Best AI Struggles at Critiquing Code
25 Aug 2025
CRITICBENCH reveals how critique ability scales in LLMs, from self-critique to code evaluation, highlighting when AI becomes a true critic.
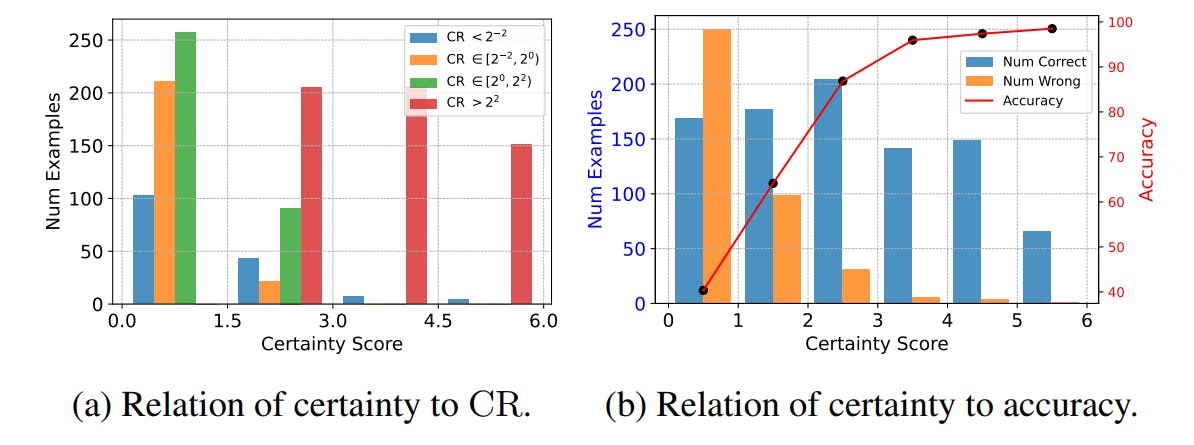
Are Your AI Benchmarks Fooling You?
25 Aug 2025
CRITICBENCH refines AI benchmarking with high-quality, certainty-based data selection to build fairer, more differentiable LLM evaluations.
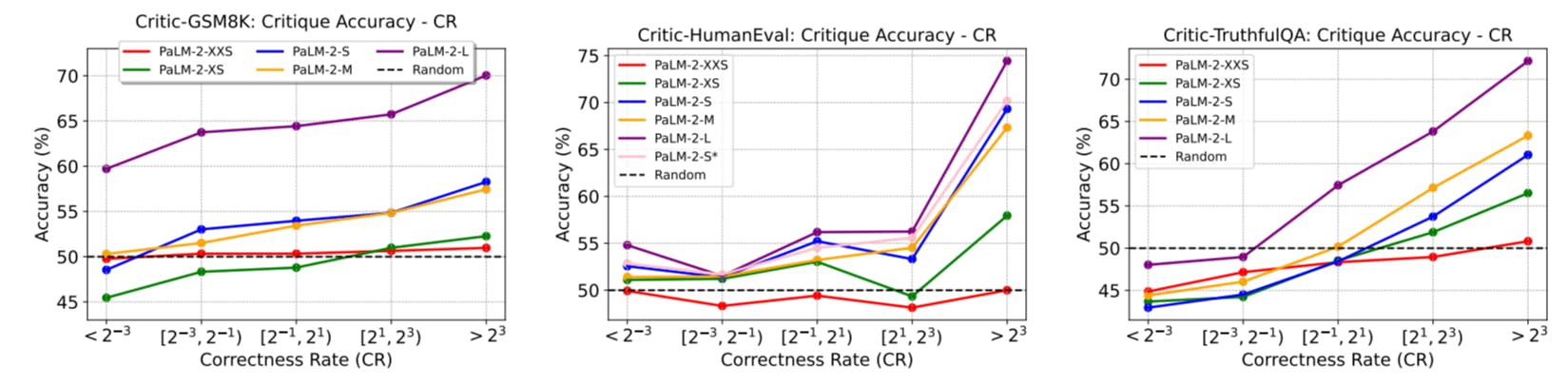
Constructing CRITICBENCH: Scalable, Generalizable, and High-Quality LLM Evaluation
25 Aug 2025
CRITICBENCH sets a new standard for evaluating LLM critiques—scalable, generalizable, and focused on quality across diverse tasks.