
Table of Links
B. CriticBench: Sources of Queries
C. CriticBench: Data Generation Details
D. CriticBench: Data Selection Details
E. CriticBench: Statistics and Examples
4.2 SELF-CRITIQUE ABILITY
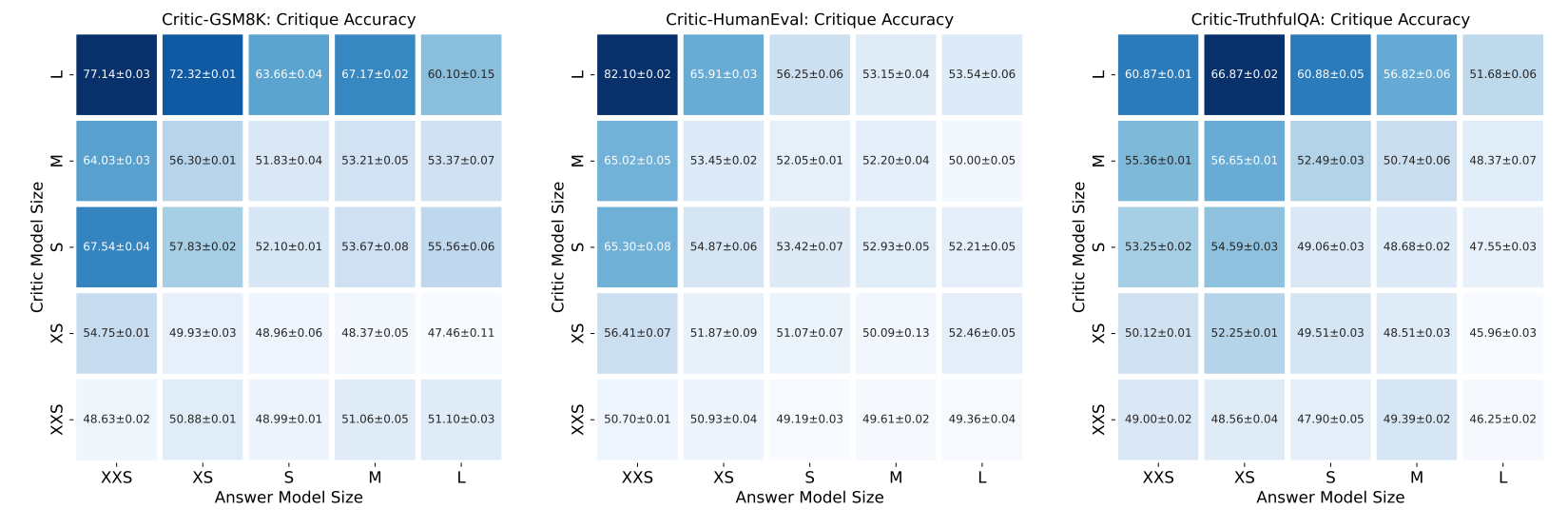
We now turn our attention to self-critique ability, a concept of particular interest due to its high relevance to a model’s potential of self-improvement. Figure 4 demonstrates the critique performance
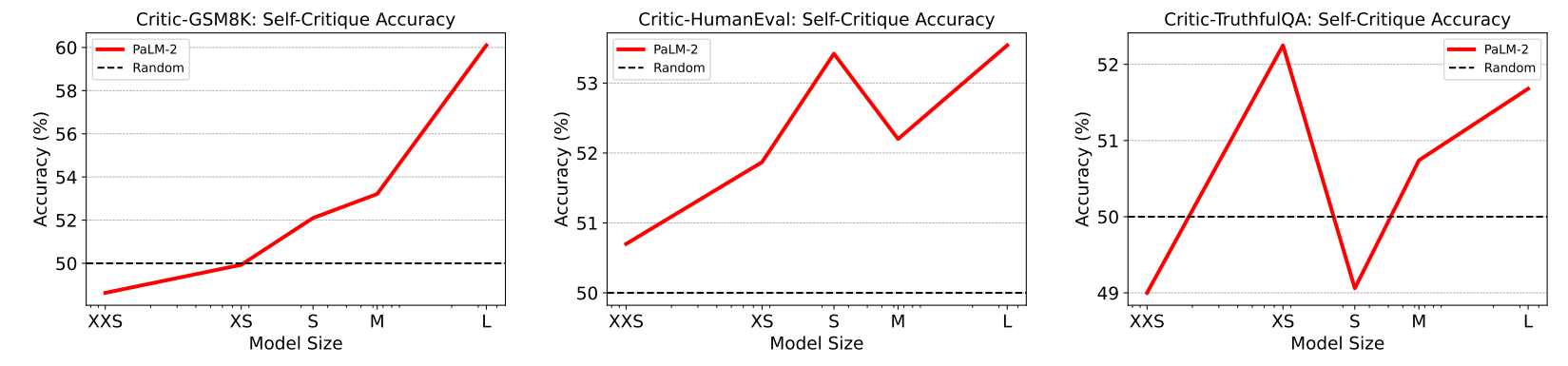
of various sizes of critic models in evaluating answers produced by different-sized policy models. The diagonal lines spanning from the lower left to the upper right represent the models’ self-critique accuracy, and correspond to the curves in Figure 5.
The scaling behavior varies across different subsets. It is unsurprising that models of all sizes struggle on Critic-HumanEval due to its challenging nature. On Critic-GSM8K, larger models display better self-critique ability. On Critic-TruthfulQA, however, models perform similarly to random guessing regardless of model size. We hypothesize the disparity is due to the underlying reasons of a model answering incorrectly to queries. For TruthfulQA, the wrong answers largely stem from false beliefs or misconceptions in models, which would also lead to critique failures. In contrast, for the math queries in GSM8K, incorrect responses primarily result from reasoning or computational flaws, which are likely detectable upon a double check through self-critiquing.
Another finding is larger models are generally good at critiquing responses generated by smaller models. The outcome aligns with the expectation that smaller models are more prone to more obvious errors, which are easier caught by larger and more capable models.
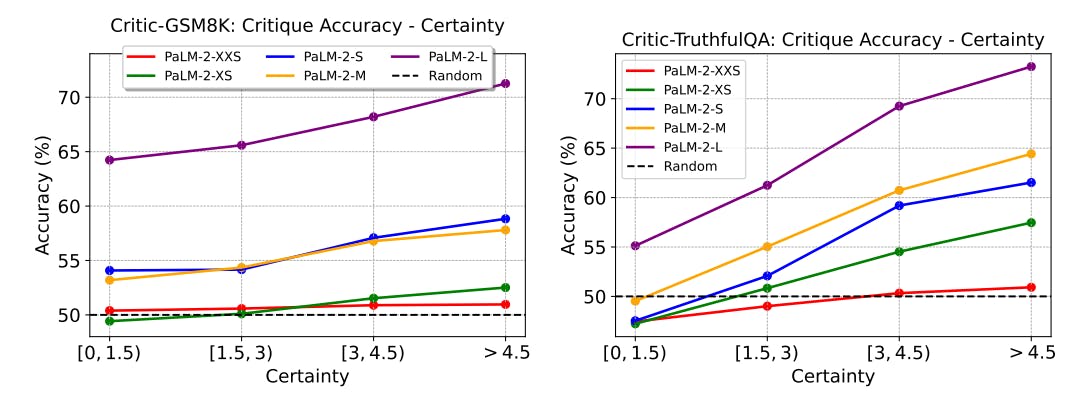
4.3 CORRELATION TO CERTAINTY
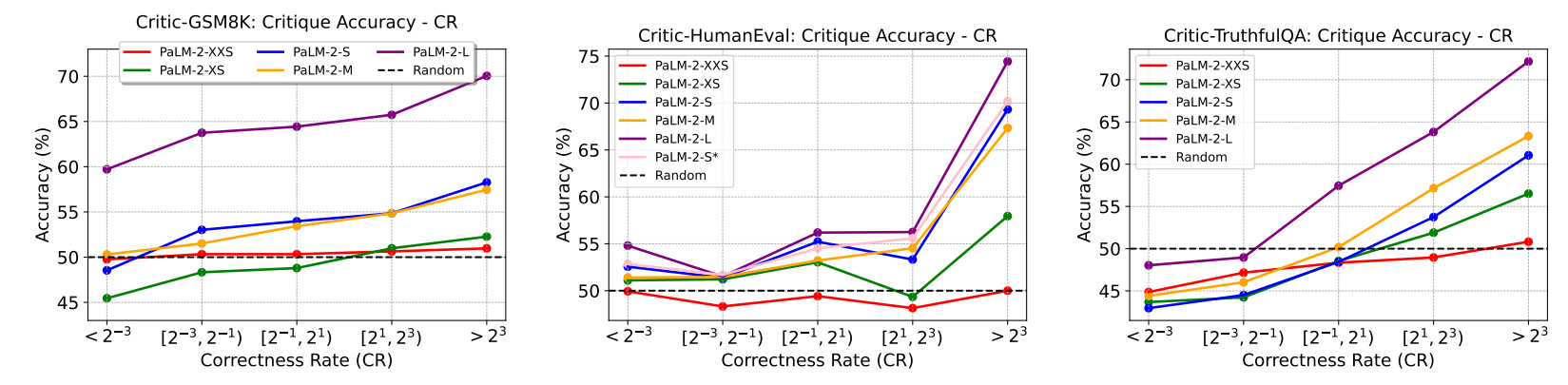
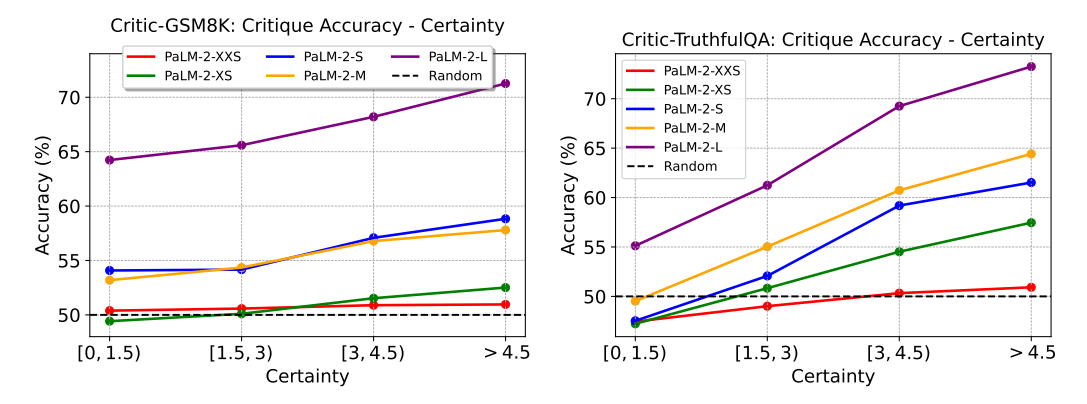
In Section 3.2.2, we introduce the use of certainty metrics to select queries of appropriate difficulty. While the metrics do reflect the challenge of answering a query, one may argue that it does not directly translate to the difficulty of critiquing an answer to that query. To address this, we examine the correlation between critique accuracy and model certainty for a query. We evaluate PaLM-2 models on the benchmarks without applying certainty-based selection. Figures 6 and 7 display the correlation between critique ability, correctness rate, and certainty score. Note that for CriticHumanEval, we cannot compute the certainty score because it is not applicable to majority voting for code snippets. Additionally, the correctness rate is calculated differently as detailed in Section 3.2.2.
We observe a clear positive correlation between model certainty and critique accuracy. This suggests that a challenging query is not only difficult for LLMs to directly answer correctly, but also poses a challenge in evaluating an answer’s correctness to the query. Consequently, the proposed certainty metrics serve as valuable criteria for data selection.
Authors:
(1) Liangchen Luo, Google Research ([email protected]);
(2) Zi Lin, UC San Diego;
(3) Yinxiao Liu, Google Research;
(4) Yun Zhu, Google Research;
(5) Jingbo Shang, UC San Diego;
(6) Lei Meng, Google Research ([email protected]).
This paper is