
Table of Links
3.2 Measuring Learning with Coding and Math Benchmarks (target domain evaluation)
3.3 Forgetting Metrics (source domain evaluation)
4 Results
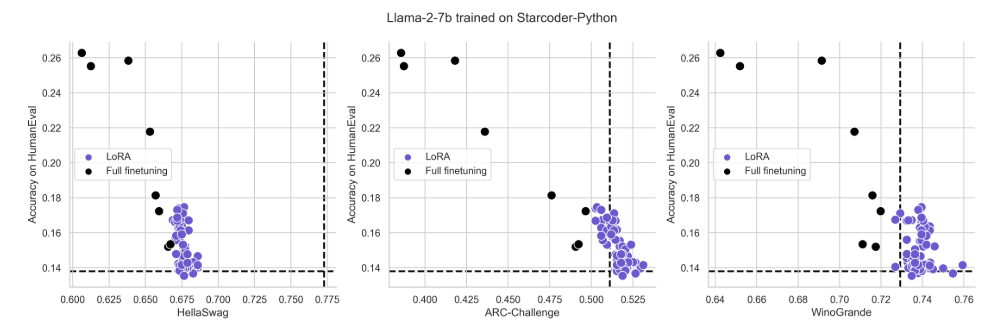
4.1 LoRA underperforms full finetuning in programming and math tasks
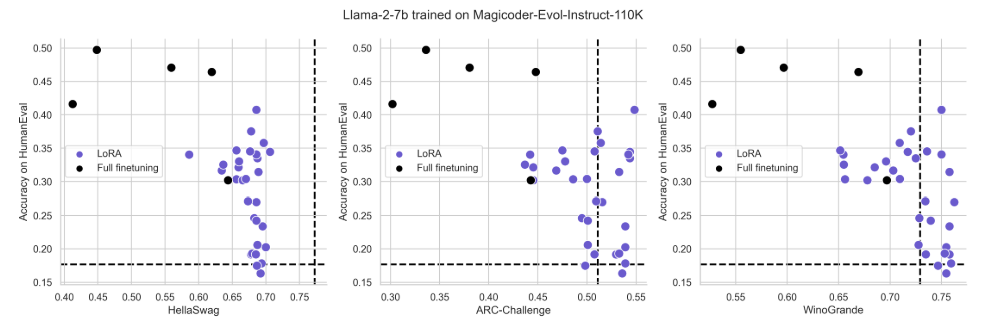
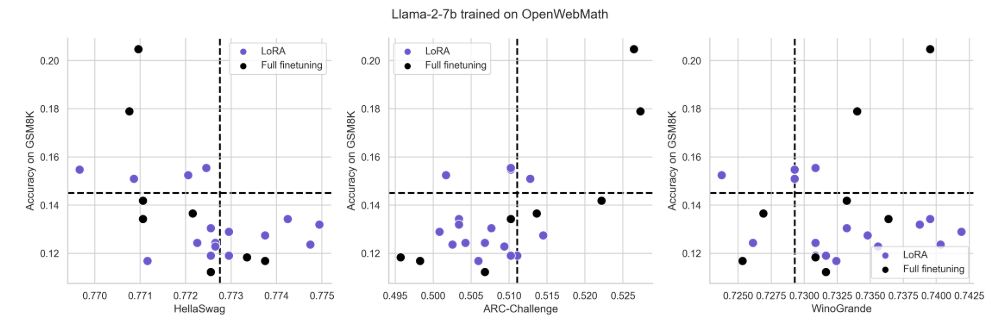
4.2 LoRA forgets less than full finetuning
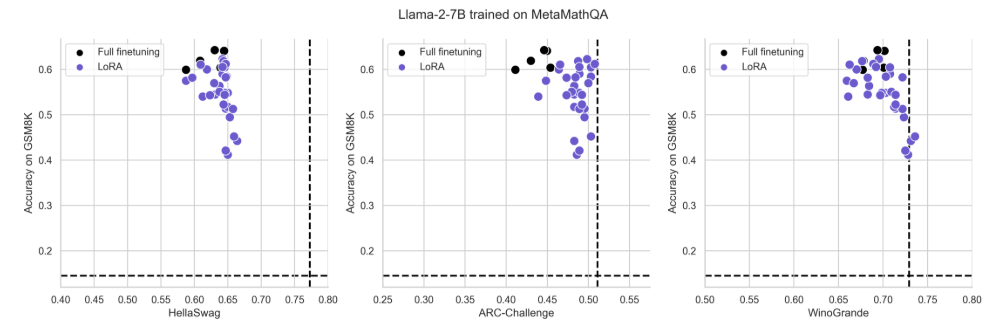
4.3 The Learning-Forgetting Tradeoff
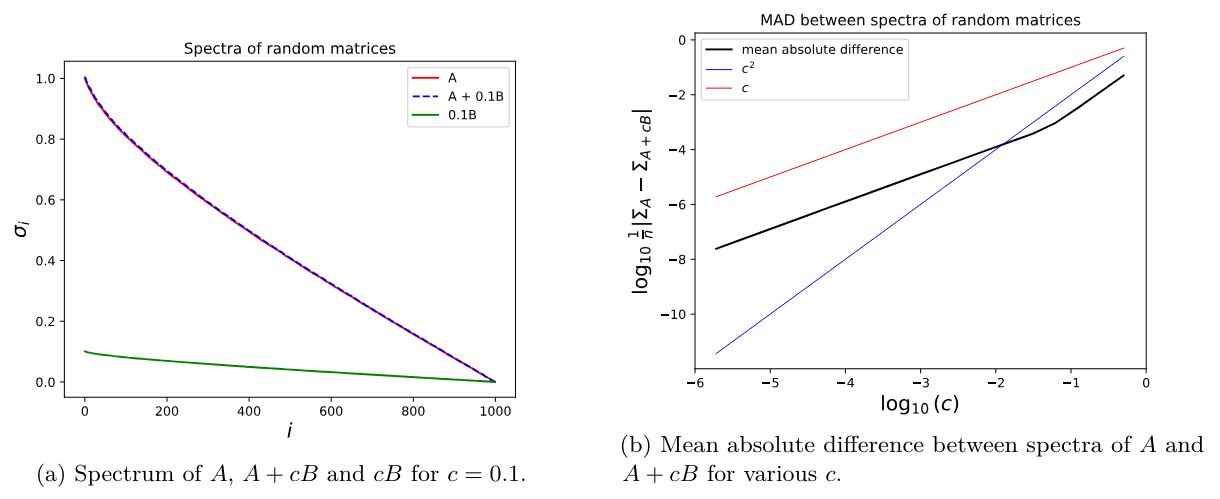
4.4 LoRA’s regularization properties
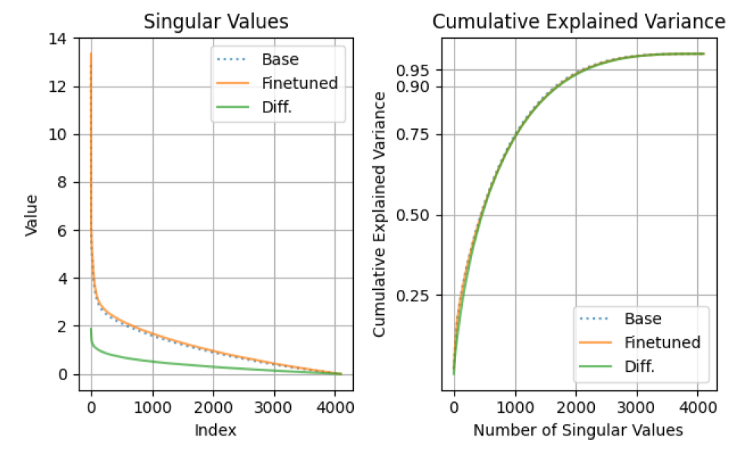
4.5 Full finetuning on code and math does not learn low-rank perturbations
4.6 Practical takeaways for optimally configuring LoRA
Appendix
D. Theoretical Memory Efficiency Gains with LoRA for Single and Multi-GPU Settings
A Experimental Setup
Code CPT.

Math CPT.

Code IFT.

Math IFT. Same as code IFT, except that
• maximum sequence length = 1024
We compared the two optimizers by training for two epochs of Magicoder-Evol-Instruct-110K using different learning rates. We found that Decoupled LionW outperformed DecoupledAdamW on HumanEval for both LoRA and full finetuning, and across learning rates, as seen in Fig. S1.
B Learning rate searches
For IFT we find that LoRA LRs should be an order of magnitude higher. For the longer CPT, these effects are more subtle.
B.1 Learning rate sensitivity analysis across optimizers
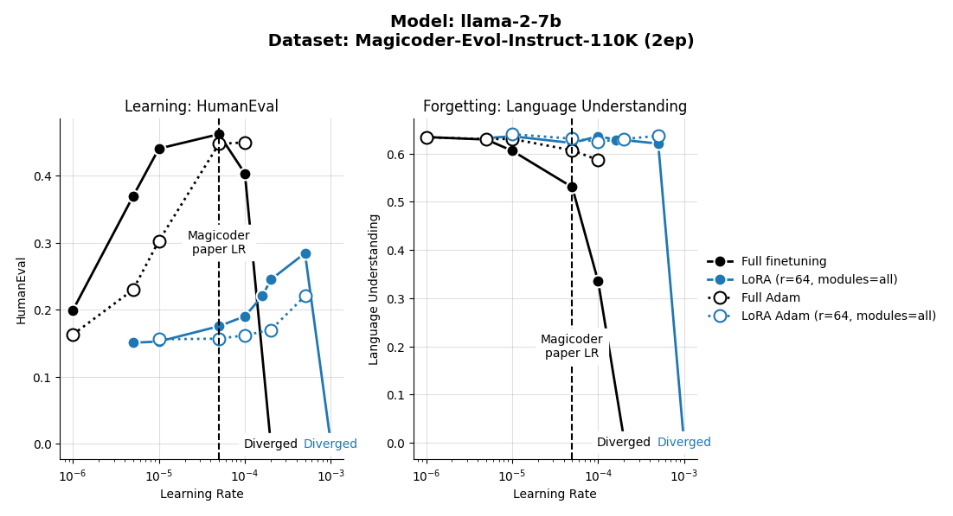
Figure S4: Same data as Fig. 3
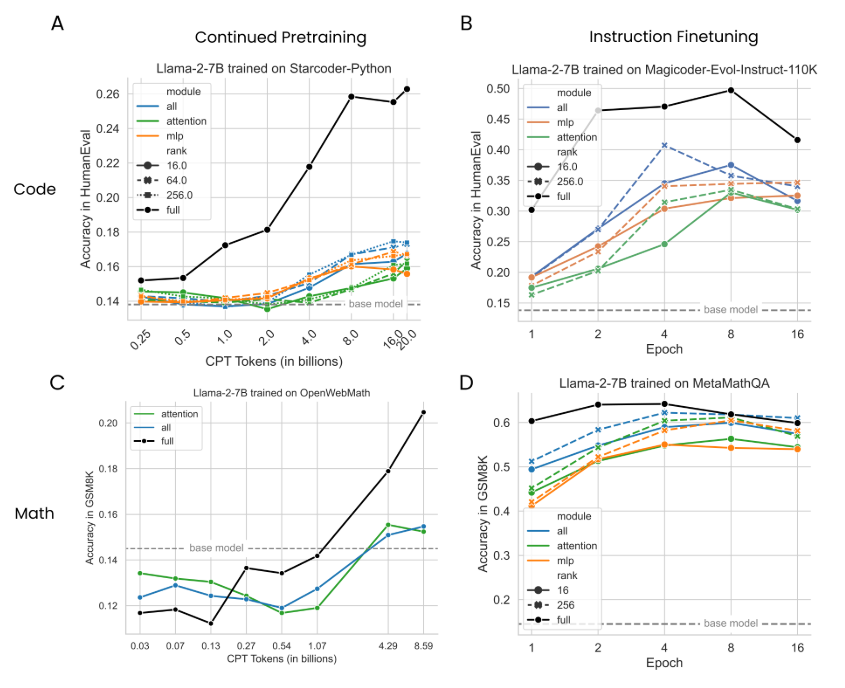

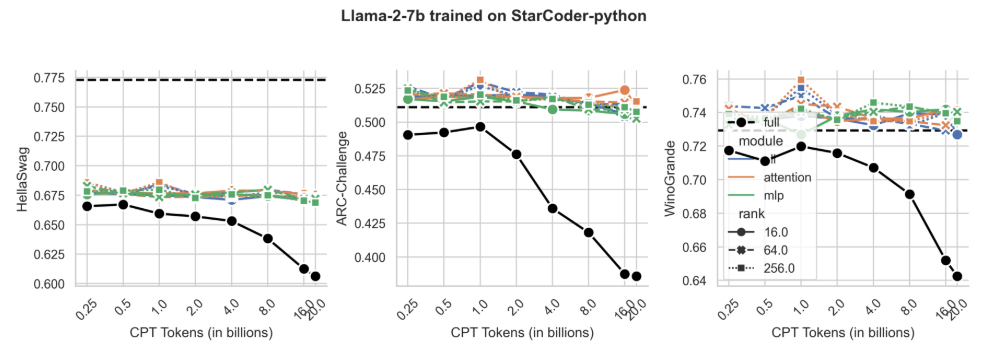
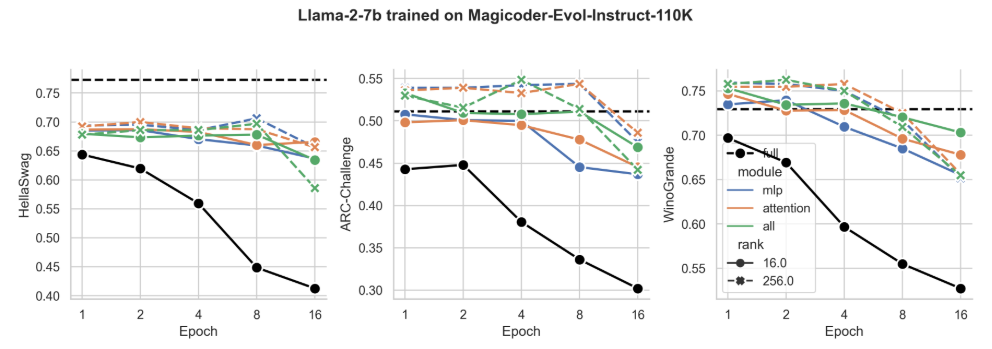
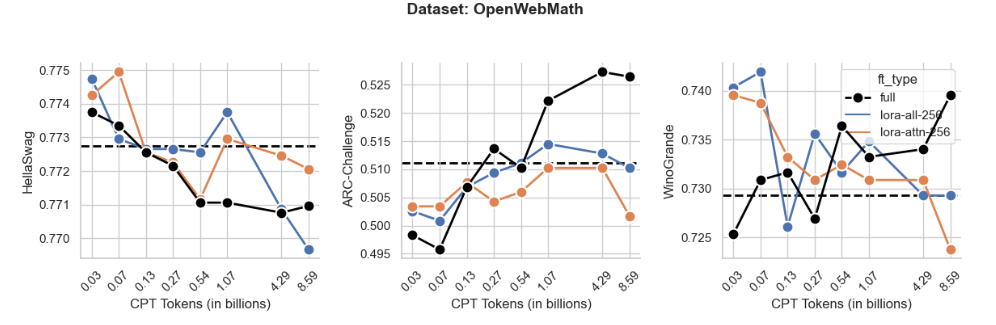
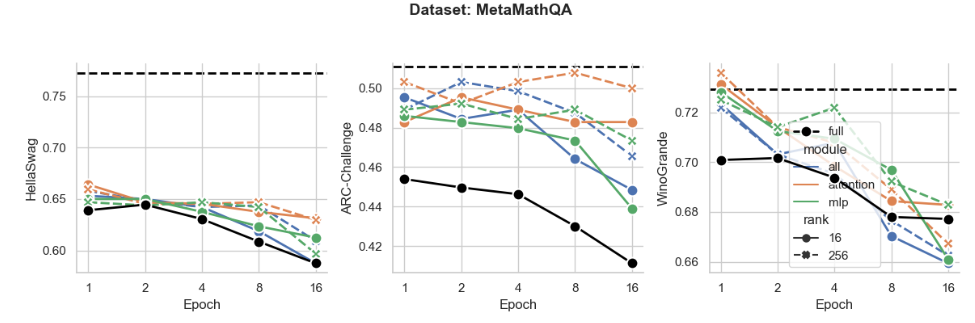
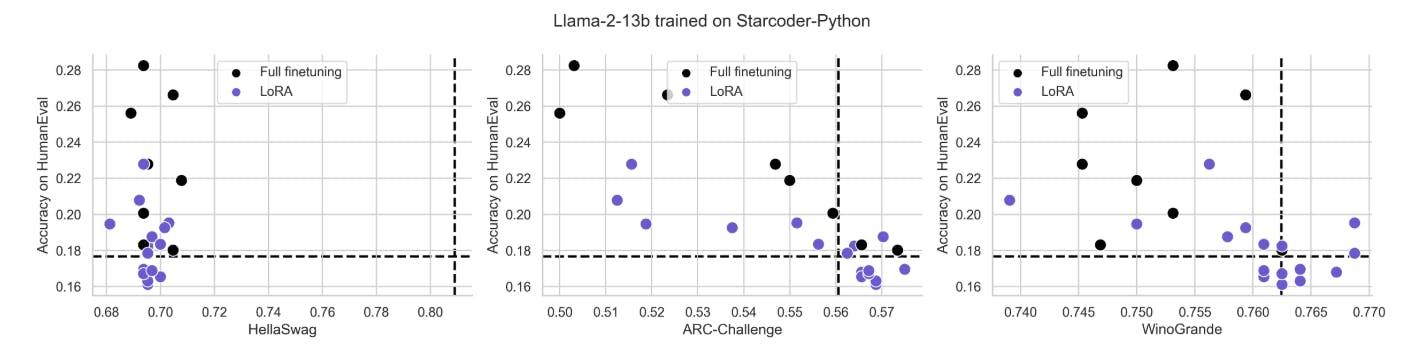
Figure S5: Same data as in Fig. 4 plotted for individual tasks HellaSwag, ARC-Challenge and WinoGrande
Authors:
(1) Dan Biderman, Columbia University and Databricks Mosaic AI ([email protected]);
(2) Jose Gonzalez Ortiz, Databricks Mosaic AI ([email protected]);
(3) Jacob Portes, Databricks Mosaic AI ([email protected]);
(4) Mansheej Paul, Databricks Mosaic AI ([email protected]);
(5) Philip Greengard, Columbia University ([email protected]);
(6) Connor Jennings, Databricks Mosaic AI ([email protected]);
(7) Daniel King, Databricks Mosaic AI ([email protected]);
(8) Sam Havens, Databricks Mosaic AI ([email protected]);
(9) Vitaliy Chiley, Databricks Mosaic AI ([email protected]);
(10) Jonathan Frankle, Databricks Mosaic AI ([email protected]);
(11) Cody Blakeney, Databricks Mosaic AI (cody.blakeney);
(12) John P. Cunningham, Columbia University ([email protected]).
This paper is