

Table of Links
3.1. Benefits scale with model size and 3.2. Faster inference
3.3. Learning global patterns with multi-byte prediction and 3.4. Searching for the optimal n
3.5. Training for multiple epochs and 3.6. Finetuning multi-token predictors
3.7. Multi-token prediction on natural language
4. Ablations on synthetic data and 4.1. Induction capability
5. Why does it work? Some speculation and 5.1. Lookahead reinforces choice points
5.2. Information-theoretic argument
7. Conclusion, Impact statement, Environmental impact, Acknowledgements, and References
A. Additional results on self-speculative decoding
E. Additional results on model scaling behavior
F. Details on CodeContests finetuning
G. Additional results on natural language benchmarks
H. Additional results on abstractive text summarization
I. Additional results on mathematical reasoning in natural language
J. Additional results on induction learning
K. Additional results on algorithmic reasoning
L. Additional intuitions on multi-token prediction
Abstract
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3× faster at inference, even with large batch sizes.
1. Introduction
Humanity has condensed its most ingenious undertakings, surprising findings and beautiful productions into text. Large Language Models (LLMs) trained on all of these corpora are able to extract impressive amounts of world knowledge, as well as basic reasoning capabilities by implementing a simple—yet powerful—unsupervised learning task: next-token prediction. Despite the recent wave of impressive achievements (OpenAI, 2023), next-token pre- *Equal contribution +Last authors 1 FAIR at Meta 2CERMICS Ecole des Ponts ParisTech 3LISN Université Paris-Saclay. Correspondence to: Fabian Gloeckle , Badr Youbi Idrissi. diction remains an inefficient way of acquiring language, world knowledge and reasoning capabilities. More precisely, teacher forcing with next-token prediction latches on local patterns and overlooks “hard” decisions. Consequently, it remains a fact that state-of-the-art next-token predictors call for orders of magnitude more data than human children to arrive at the same level of fluency (Frank, 2023).
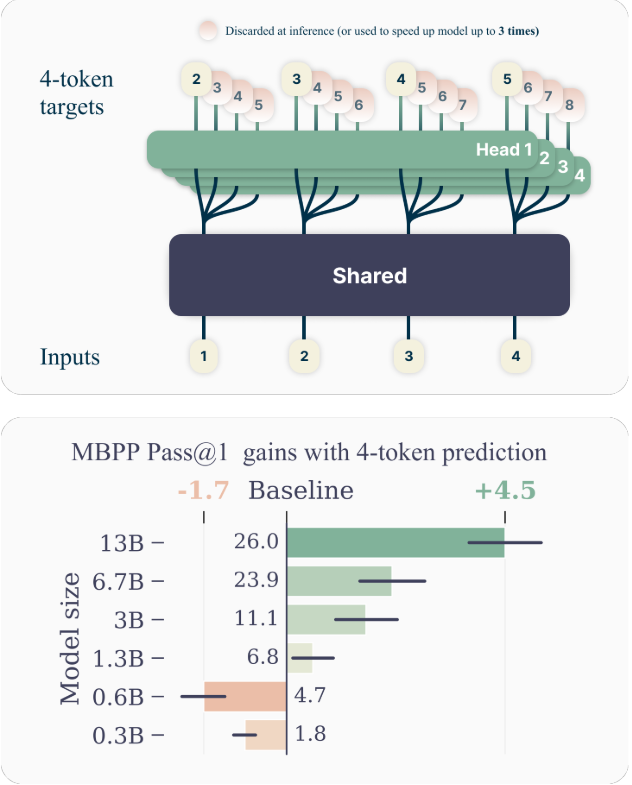
In this study, we argue that training LLMs to predict multiple tokens at once will drive these models toward better sample efficiency. As anticipated in Figure 1, multi-token prediction instructs the LLM to predict the n future tokens from each position in the training corpora, all at once and in parallel (Qi et al., 2020).
Contributions While multi-token prediction has been studied in previous literature (Qi et al., 2020), the present work offers the following contributions:
-
We propose a simple multi-token prediction architecture with no train time or memory overhead (Section 2).
-
We provide experimental evidence that this training paradigm is beneficial at scale, with models up to 13B parameters solving around 15% more code problems on average (Section 3).
-
Multi-token prediction enables self-speculative decoding, making models up to 3 times faster at inference time across a wide range of batch-sizes (Section 3.2).
While cost-free and simple, multi-token prediction is an effective modification to train stronger and faster transformer models. We hope that our work spurs interest in novel auxiliary losses for LLMs well beyond next-token prediction, as to improve the performance, coherence, and reasoning abilities of these fascinating models.
This paper is available on arxiv under CC BY 4.0 DEED license.
Authors:
(1) Fabian Gloeckle, FAIR at Meta, CERMICS Ecole des Ponts ParisTech, and contributed equally;
(2) Badr Youbi IdrissiFAIR at Meta, LISN Université Paris-Saclay, and contributed equally;
(3) Baptiste Rozière, FAIR at Meta;
(4) David Lopez-Paz, FAIR at Meta and his the last author;
(5) Gabriel Synnaeve, FAIR at Meta and the last author.