

Table of Links
3.1. Benefits scale with model size and 3.2. Faster inference
3.3. Learning global patterns with multi-byte prediction and 3.4. Searching for the optimal n
3.5. Training for multiple epochs and 3.6. Finetuning multi-token predictors
3.7. Multi-token prediction on natural language
4. Ablations on synthetic data and 4.1. Induction capability
5. Why does it work? Some speculation and 5.1. Lookahead reinforces choice points
5.2. Information-theoretic argument
7. Conclusion, Impact statement, Environmental impact, Acknowledgements, and References
A. Additional results on self-speculative decoding
E. Additional results on model scaling behavior
F. Details on CodeContests finetuning
G. Additional results on natural language benchmarks
H. Additional results on abstractive text summarization
I. Additional results on mathematical reasoning in natural language
J. Additional results on induction learning
K. Additional results on algorithmic reasoning
L. Additional intuitions on multi-token prediction
3.5. Training for multiple epochs
Multi-token training still maintains an edge on next-token prediction when trained on multiple epochs of the same data. The improvements diminish but we still have a +2.4% increase on pass@1 on MBPP and +3.2% increase on pass@100 on HumanEval, while having similar performance for the rest. As for APPS/Intro, a window size of 4 was already not optimal with 200B tokens of training.
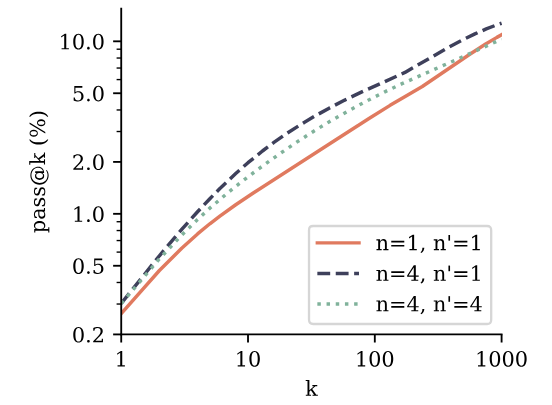
3.6. Finetuning multi-token predictors
Pretrained models with multi-token prediction loss also outperform next-token models for use in finetunings. We evaluate this by finetuning 7B parameter models from Section 3.3 on the CodeContests dataset (Li et al., 2022). We compare the 4-token prediction model with the next-token prediction baseline, and include a setting where the 4-token prediction model is stripped off its additional prediction heads and finetuned using the classical next-token prediction target. According to the results in Figure 4, both ways of finetuning the 4-token prediction model outperform the next-token prediction model on pass@k across k. This means the models are both better at understanding and solving the task and at generating diverse answers. Note that CodeContests is the most challenging coding benchmark we evaluate in this study. Next-token prediction finetuning on top of 4-token prediction pretraining appears to be the best method overall, in line with the classical paradigm of pretraining with auxiliary tasks followed by task-specific finetuning. Please refer to Appendix F for details.
This paper is available on arxiv under CC BY 4.0 DEED license.
Authors:
(1) Fabian Gloeckle, FAIR at Meta, CERMICS Ecole des Ponts ParisTech, and contributed equally;
(2) Badr Youbi IdrissiFAIR at Meta, LISN Université Paris-Saclay, and contributed equally;
(3) Baptiste Rozière, FAIR at Meta;
(4) David Lopez-Paz, FAIR at Meta and his the last author;
(5) Gabriel Synnaeve, FAIR at Meta and his the last author.