

Table of Links
3.1. Benefits scale with model size and 3.2. Faster inference
3.3. Learning global patterns with multi-byte prediction and 3.4. Searching for the optimal n
3.5. Training for multiple epochs and 3.6. Finetuning multi-token predictors
3.7. Multi-token prediction on natural language
4. Ablations on synthetic data and 4.1. Induction capability
5. Why does it work? Some speculation and 5.1. Lookahead reinforces choice points
5.2. Information-theoretic argument
7. Conclusion, Impact statement, Environmental impact, Acknowledgements, and References
A. Additional results on self-speculative decoding
E. Additional results on model scaling behavior
F. Details on CodeContests finetuning
G. Additional results on natural language benchmarks
H. Additional results on abstractive text summarization
I. Additional results on mathematical reasoning in natural language
J. Additional results on induction learning
K. Additional results on algorithmic reasoning
L. Additional intuitions on multi-token prediction
K. Additional results on algorithmic reasoning
We investigate the following computation-sharing hypothesis for explaining the efficacy of multi-token prediction as training loss.
The prediction difficulty of different tokens in natural text varies greatly. Some tokens may be the continuations of partial words that are uniquely determined from their preceding context without any effort, while others may require to predict theorem names in difficult mathematical proofs or the correct answer to an exam question. Language models with residual connections have been shown to refine their output token distribution with each successive layer, and can be trained with early exit strategies that spend variable amounts of computational resources per token position. Multi-token prediction losses explicitly encourage information-sharing between adjacent token positions and can thus be viewed as a method to learn allocating computational resources in language models more efficiently to the tokens that benefit most of it.
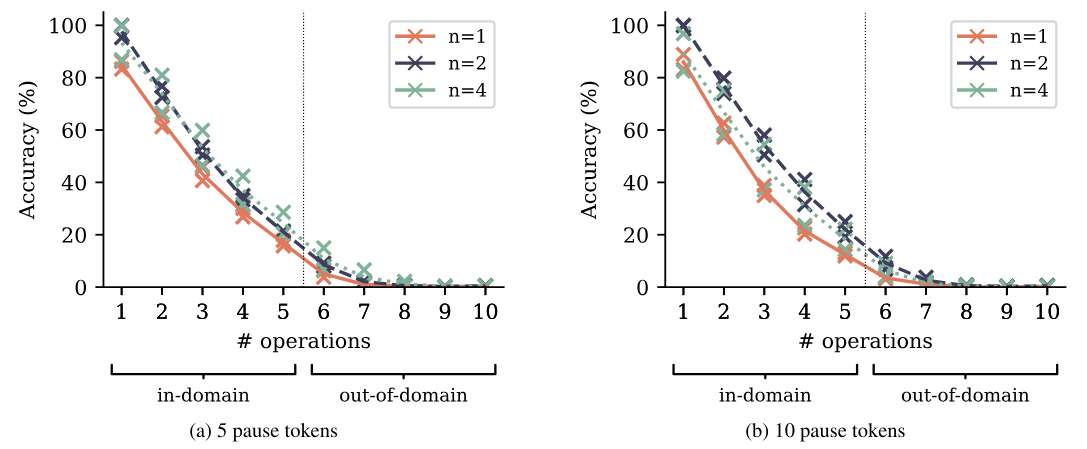
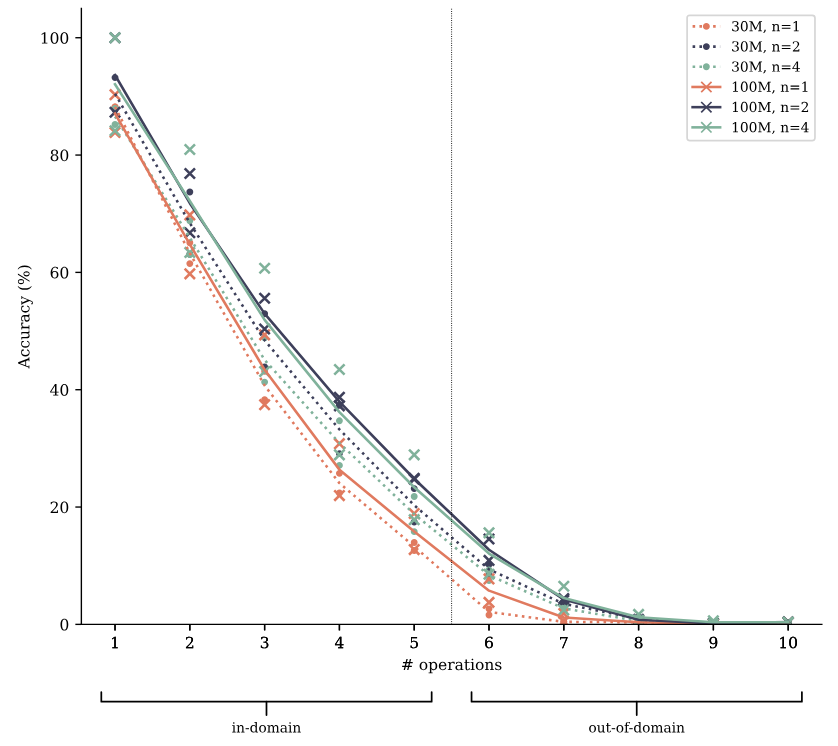
To check the truth of this hypothesis, we augment the polynomial arithmetic task from Section 4.2 with a varying number of pause tokens (Goyal et al., 2023) inserted between the question and a token that denotes the beginning of the answer. Pause tokens introduce additional computational resources that can be expended for computations that are expected to be useful later on in the sequence, in other words: to start thinking about the answer. According to the computation-sharing hypothesis, multi-token prediction models learn information-sharing and thus computation-sharing between token positions more easily, and may be better at making use of these additional computational resources than next-token prediction models are. In Figure S15, we show the evaluation results on the polynomial arithmetic task with a fixed number of pause tokens inserted both at training and evaluation time. Multi-token prediction models likewise outperform next-token prediction models on these task variants across task difficulties and model sizes. However, we do not see strong evidence of a widening or shrinking of this gap i.e. we cannot conclude from these experiments on the veracity of the computation-sharing hypothesis.
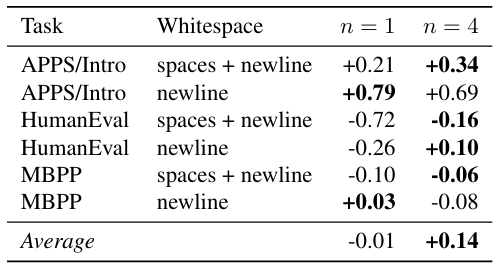
In Table S11, we report results from another experiment in the same spirit: by adding spaces and newlines to HumanEval and MBPP prompts, we add “pause tokens” in a somewhat natural way. According to these results, multi-token prediction models have a slight advantage at using this additionally provided compute, but the effect is marginal.

This paper is available on arxiv under CC BY 4.0 DEED license.
Authors:
(1) Fabian Gloeckle, FAIR at Meta, CERMICS Ecole des Ponts ParisTech, and contributed equally;
(2) Badr Youbi IdrissiFAIR at Meta, LISN Université Paris-Saclay, and contributed equally;
(3) Baptiste Rozière, FAIR at Meta;
(4) David Lopez-Paz, FAIR at Meta and his the last author;
(5) Gabriel Synnaeve, FAIR at Meta and the last author.