
Table of Links
B. CriticBench: Sources of Queries
C. CriticBench: Data Generation Details
D. CriticBench: Data Selection Details
E. CriticBench: Statistics and Examples
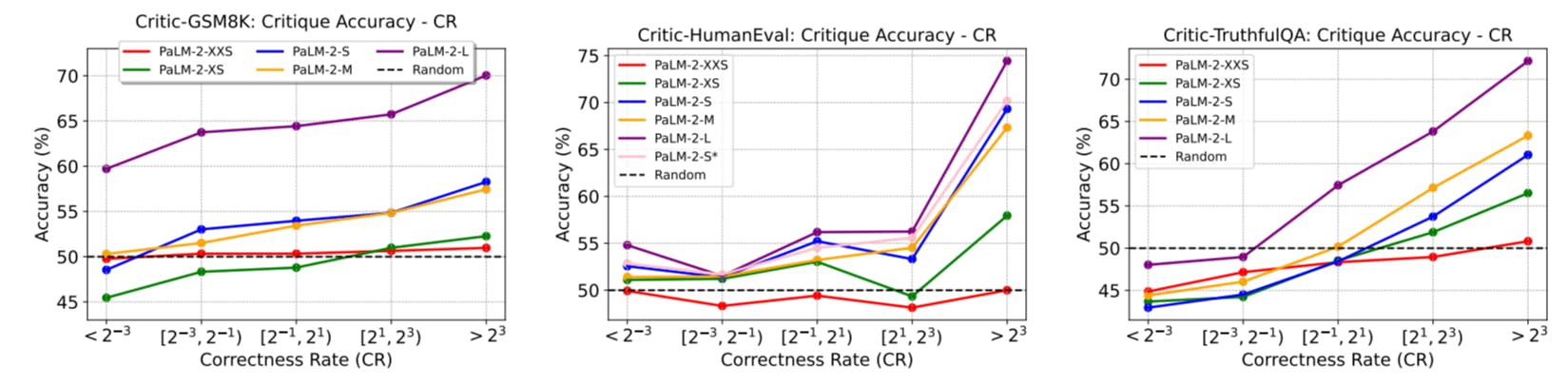
3 CONSTRUCTION OF CRITICBENCH
As discussed in Section 2, prior research employs large language models to offer critiques, yet requires particular process and formats to meet their task-specific objectives. Currently, there is no standard or generalizable way to assess the critique abilities of language models across diverse tasks. This section proposes CRITICBENCH, a unified, standardized evaluation framework to tackle this issue. The framework aims to fulfill three criteria:
• Scalability Given the broad range of tasks already established within the community, and the anticipation of more to emerge, a scalable data collection method is essential. The method should minimize human annotation efforts and ideally be fully autonomous.
• Generalizability The framework should be task-agnostic, capable of generalizing across various tasks and domains.
• Quality We believe quality matters more than quantity. When volume of data is substantial, we prioritize selecting those that most effectively differentiate between stronger and weaker models.
The following subsections illustrate the detailed construction process. Specifically, Section 3.1 presents the initial data generation on three different tasks, where we get the collection of queryresponse-judgment triplets as shown in Figure 1. Section 3.2 then shows how to select data based on the initial collection to guarantee the quality of responses and queries.
3.1 DATA GENERATION
For the tasks of interest, we begin by employing existing scientific datasets from relevant domains. These datasets are expected to include queries that large language models, which here we refer to as generators, aim to respond.
To ensure scalability, it is essential to have an automated approach for assessing the correctness of a model’s responses. Classification tasks naturally meet this criterion, as model outputs can be automatically compared to ground-truth labels. Similarly, tasks that involve auto-verifiable answers also comply; for instance, in code completion tasks with unit tests available, the validity of the generated code can be confirmed by passing all tests. For free-form generation tasks such as summarization and translation, assessing the quality of a response remains non-trivial. However, recent advances in LLM-based automated evaluation for generation tasks mitigate this issue to some extent, enabling the assessment without human intervention (Liu et al., 2023).
While not exhaustive, these already cover a significant range of tasks and domains. We acknowledge the limitations in some auto-assessment approaches, especially for generation tasks. Improving the reliability of these automated evaluation methods, however, is beyond the scope of this paper.
We employ five different sizes of PaLM-2 models (Google et al., 2023) as our generators. These models are pretrained solely for next-token prediction and do not undergo supervised fine-tuning or reinforcement learning from human feedback. For coding-related tasks, apart from the standard PaLM-2 models, we also employ the specialized PaLM-2-S* variant. The latter is obtained through continual training of PaLM-2-S on a data mixture enriched with code-heavy corpus.
Query Collection We extract queries from three datasets: GSM8K (Cobbe et al., 2021), HumanEval (Chen et al., 2021), and TruthfulQA (Lin et al., 2021), covering the tasks of math-problem solving, code completion and question answering. For datasets with distinct training and test splits, we use the test data; for datasets intended only for evaluation, all examples are used. Detailed considerations and rationale behind the selection of these datasets are provided in Appendix B.
Response Generation We sample k responses for each query, with k = 64 for GSM8K and TruthfulQA, and k = 100 for HumanEval. In the case of TruthfulQA, we employ its multiplechoice variation to facilitate autonomous answer annotation. After filtering out invalid outputs such as empty ones, we collect a total of 780K responses as an initial pool of candidates.
Annotation for Correctness For GSM8K, we assess answer correctness by comparing its numeric equality to the ground truth, as described by Lewkowycz et al. (2022). For HumanEval, correctness is determined by the passage of provided unit tests. For TruthfulQA, we utilize its classification format, judging correctness based on a match with the ground-truth label.
More details on hyper-parameter settings and prompt templates are available in Appendix C.
Authors:
(1) Liangchen Luo, Google Research ([email protected]);
(2) Zi Lin, UC San Diego;
(3) Yinxiao Liu, Google Research;
(4) Yun Zhu, Google Research;
(5) Jingbo Shang, UC San Diego;
(6) Lei Meng, Google Research ([email protected]).
This paper is